
It happens all the time: Sitting at Starbucks with friends or driving to work and there’s some awesome song playing on the FM radio station, you ask your friend what is the name of the song, “Just Shazam it” might be the common answer.
Yes, like Google and Twitter, Shazam became the verb now. When a product name becomes a verb, it means that the brand has hit the big time. It has been reported that Shazam now has more than 120 million monthly active users, and became one of the most popular app in the world.
So, what is the technology behind this well-known music finder app?
It’s called audio fingerprinting, and it provides the ability to link short, unlabeled pieces of audio content to corresponding meta data about that content. Audio fingerprinting enable users to identify the song title by providing a small piece of audio sample of the song instead of entering some keywords to look for.
Requirement
Before introducing the specific algorithm adopted by Shazam, it is relevant to list some of the typical desired technology properties for fingerprint extracting and matching. A good fingerprinting algorithm should be:
| Properties | Requirement |
| Robust | The ability of the audio feature representation to withstand the perturbations such as additive noise or distortions brought by compression algorithms. |
| Unique | The discriminative abilities of the fingerprints to avoid collision probability. It should be discriminative enough to tell the difference of that two dissimilar audio should generate two different fingerprints. |
| Accurate | The basic requirement for accurate property should be related heavily to robustness and uniqueness as mentioned above. What is more important, the accuracy for time localization, such as the ability to locate accurately the starting and ending point of a query fragment located in the target audio in database. |
| Granularity | The minimum query length required for identification. A system is fine granular this means that it is capable of reliable identification of small pieces of example. |
| Compact | To meet the real world application, the fingerprint size should be small to minimize the cost of computing resources. |
| Scalability | Again, to build a real world service, the fingerprinting algorithm and infrastructure should be scalable to a huge number of fingerprint, for example, tens of millions of songs, and tens of millions of daily queries. |
Technology
With the above requirements, now let’s go through to see how shazam’s algorithm works.
The algorithm developed by Avery Wang in has been cited more than four hundred times in google scholar (this number is huge in such area of research) and it’s known to have good performance and gives a comprehensive overview of the fast and computationally efficient fingerprinting algorithm.
Like most other sound recognition algorithms, Shazam’s approach starts with a spectrographic view of the data: Turns the time-domain input audio signal into frequency domain, then finds peaks in the spectrogram – the time-frequency pairs with the highest energy. These pairs, which occupy much less storage than the original spectrogram, are then indexed into a database associate with music meta-info and time offset. The algorithm can be described as follows:
Step 1: Converting the time domain music signal to spectrogram
Assume that the music signal is short-time stationary. First the input signal is cut into small pieces by hamming windows. Then STFTs are used to determine the frequency content of the windows signal.
Step 2: Find Landmarks
Just as human fingerprint feature representation, the landmarks are the unique identifying characteristics of the input signal, and are mostly invariant characteristics by signal distortion and noise.

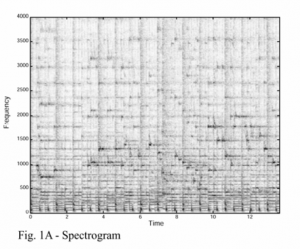
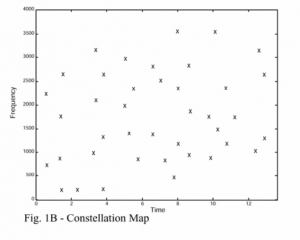
Find Landmarks is the key step of song identification. This step takes the spectrogram of the song as input and gets a set of Landmarks as output. Below, we will explain the series of steps that we follow to identify the landmarks of our song.
1. Input Spectrogram
2. Convert to Log Domain
3. Remove the Mean
4. High Pass Filter Data to remove slowly varying terms
5. Forward Pruning using a thresholding envelope
6. Backward Pruning using a thresholding envelope
7. Landmark Generation
Step 3: Hashing (Build the database)
The hash table works by calculating all the landmarks for an audio, as well as the time at which they occur. Then the time information and the music ID are packed into a single 32 bit number and stored in the hash table as the key.
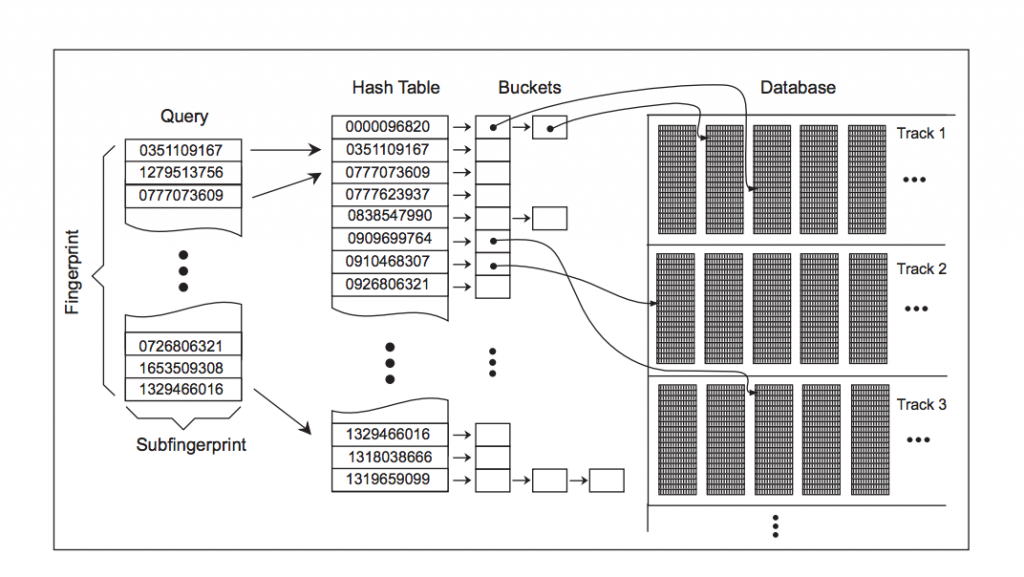
In the matching step, the matching hashes are associated with their time offsets t1 for both query and candidates. For a true match between to songs, the query and candidate time stamps have a common offset for all corresponding hashes.
The query is first compared to the fingerprints of popular items. This can include a ‘most wanted’ list, or a list of new releases. If there is no match in the short list, the query is matched to the entire fingerprint database.
Alternative algorithms
Audio fingerprinting is a well-researched domain, there are also other AFP algorithms developed, as briefed below:
The PRH algorithm developed by Haitsma et al. has been reported to have good performance and a simple and efficient structure. It was developed at Philips Research, and sold to Gracenote, Inc.
J. Haitsma and T. Kalker, A Highly Robust Audio Fingerprinting System, In Proceedings of International Conference on Music Information Retrieval, 2002.
Yan Ke and others view music signal as image, and incorporated computer vision techniques to do audio recognition.
Y. Ke, D. Hoiem, R. Sukthankar, Computer Vision for Music Identification, Proceedings of Computer Vision and Pattem Recognition, pp. 597 – 604, 2005.
S. Bahja and others also applied computer vision technology into data stream processing, and generated audio fingerprints by the Haar wavelet transform and Min Hash technology, and used Locality Sensitive Hashing(LSH) technique in audio fingerprint retrieval.
S. Bahja and M. Covell, Content Fingerprinting Using Wavelets, In Conference on Visual Media Production, pp. 198 – 207, 2006.
Scenarios
Audio fingerprinting is used for a wide variety of scenarios:
• Music Recognition
if you are wondering what song your listening to, e.g., on the radio, you can collect and send a few seconds of music using a cell phone, and any time you play an audio CD and your computer’s music player automatically looks up information about the album. This kind of service computes and matches the fingerprint, and returns metadata containing artist, song title, album etc.
According to the published data, there are billions of mobile phones and hundreds of millions of vehicles are equipped with this kind of services, and around 30 billion queries are executed monthly. This is huge, it is in the same order of magnitude of google monthly searches for text.

The screenshots above show two popular apps – Musixmtach and Peach with music recognition feature.
• Radio Airplay Monitoring
Broadcasting royalties are distributed based on music usage reports submitted by each broadcaster. By comparing and matching the audio fingerprinting of music tracks broadcast with the ones extracted from commercial music recordings, broadcast works can be quickly and efficiently identified, which made census reporting possible with less effort.
Further more, Advertisers spend money to have their commercials aired according to a contract. However, it is very time-consuming to manually check whether the commercials are actually aired according to the agreed terms. Audio Fingerprinting could automatically monitor a number of radio and television channels looking for specific content, e.g., advertisements, and register when, where, how long etc. the content is aired.

Soundcharts is an intelligence platform with big data includes music charts, radio airplay etc for music industry insiders.
• Second Screen
Second screen app is another big area for audio fingerprinting technology, more and more apps joined the game now. Second screen apps give TV industry another chance to bring the advertisers back as the second screen apps can be seen as the bridge to fill the gap between old school TV and internet. Users on the second screen apps are easily to interact with what’s playing on TV then purchase the relevant items on the apps.

Taobao is the leading e-commerce app in China under Alibaba Group, it integrates ACRCloud second screen solution to detect what’s playing on TV.
•Copyright Compliance
Copyright is always an issue of UGC websites, the system like Content ID of YouTube gives a solution of solving the copyright problem, here’s how Content ID works:
The system like Content ID using audio fingerprinting technology to match the copyrighted content in the videos uploaded by users. Soundcloud alike platform Hearthis.at uses ACRCloud’s music copyright compliance solution to build a similar system to prevent copyright abuse on its platform for UGC.
• Audience Measurement
To identify which programs the user is watching or listening to. Therefore, statistics can be generated on what kind of shows/TV are popular among people. Statistics can also be generated based on relations in the metadata collected by fingerprinting.


